Bridging Stereo Matching and Optical Flow via
Spatiotemporal Correspondence
Hsueh-Ying Lai1, Yi-Hsuan Tsai2, Wei-Chen Chiu1,
1 National Chiao Tung University,
2 NEC Labs America


Bridging Stereo Matching and Optical Flow via
Spatiotemporal Correspondence
Hsueh-Ying Lai1, Yi-Hsuan Tsai2, Wei-Chen Chiu1,
1 National Chiao Tung University,
2 NEC Labs America
Stereo matching and flow estimation are two essential tasks for scene understanding, spatially in 3D and temporally in motion. Existing approaches have been focused on the unsupervised setting due to the limited resource to obtain the large-scale ground truth data. To construct a self-learnable objective, co-related tasks are often linked together to form a joint framework. However, the prior work usually utilizes independent networks for each task, thus not allowing to learn shared feature representations across models. In this paper, we propose a single and principled network to jointly learn spatiotemporal correspondence for stereo matching and flow estimation, with a newly designed geometric connection as the unsupervised signal for temporally adjacent stereo pairs. We show that our method performs favorably against several state-of-the-art baselines for both unsupervised depth and flow estimation on the KITTI benchmark dataset.

Overall structure of our method. Our framework consists of a single model

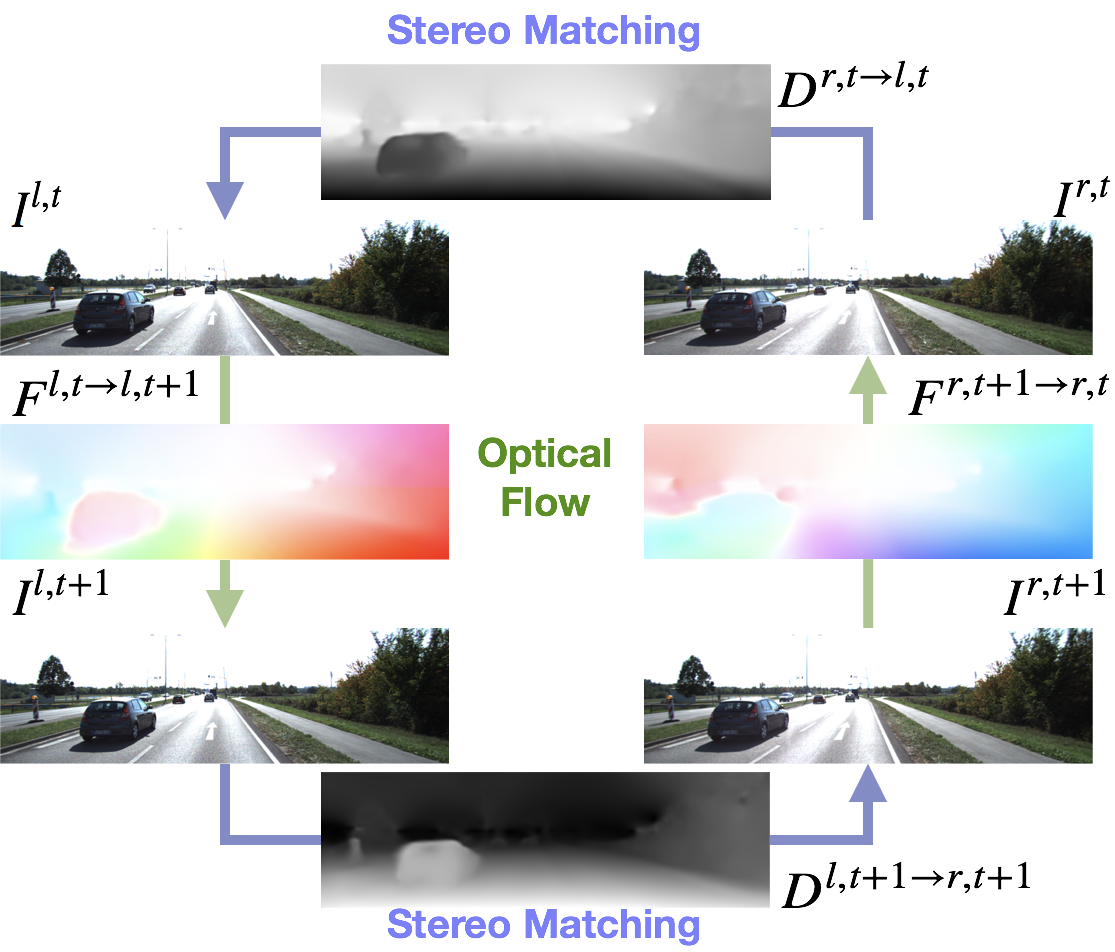
The figure above shows the concept of our proposed 2-warp method, which shows the reconstruction by warping functions through the correspondence maps from both stereo matching and optical flow. Depend on the direction of the reconstruction, the 2-warp functions can also be divided into two classes: from stereo to flow and from flow to stereo. As we adopt 2 2-warp functions on our method, there would be 3 variants of our full model.

Example results on KITTI. In each row, we sequentially show the left image at time t, our predicted depth map, the ground truth depth, our flow prediction, and the ground truth flow
Bridging Stereo Matching and Optical Flow via Spatiotemporal Correspondence
Hsueh-Ying Lai, Yi-Hsuan Tsai, Wei-Chen Chiu













 Paper (arXiv)
Paper (arXiv)
 Source Code
Source Code
@inproceedings{lai19cvpr,
title = {Bridging Stereo Matching and Optical Flow via Spatiotemporal Correspondence},
author = {Hsueh-Ying Lai and Yi-Hsuan Tsai and Wei-Chen Chiu},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}}
![]()